 Java, Spring and Web Development tutorials  1. Overview
Working with large datasets in relational databases can challenge query performance. While Hibernate provides optimizations for entity mapping, partitioning becomes essential as the dataset expands.
In this tutorial, we’re going to dive into how we can use Spring Boot to work with partitioned tables. We’ll be using Hibernate and Spring Data JPA to handle the interactions, but we’ll see that the actual partitioning is something we configure directly within the database itself, like PostgreSQL.
2. The Role of @PartitionKey
When we split a really big table into smaller, more manageable tables, it’s called partitioning. Each partition contains a subset of data, often determined by a partition key. In Hibernate, we can map a specific column as the partition key so that queries can target only the relevant partitions, drastically improving query speed.
Partitioning creates separate physical tables for each data segment. For example, a Sales table partitioned by saleDate, we might have sales_2024_q1, sales_2024_q2, and so on. This physical separation is what enables the performance gains.
We cannot simply partition an existing, large table. The process requires a migration strategy. This usually involves creating a new partitioned table structure and then migrating the data from the old table into the new one. This ensures data integrity and consistency.
The full benefit of partitioning is achieved when our queries include the partition key in their WHERE clauses. If a query doesn’t specify the partition key, the database’s query planner will likely have to search all partitions, which negates the performance benefits.
3. Setting Up PostgreSQL Database
We’ll be using PostgreSQL as our DB. Let’s create the table with a PARTITION BY clause, which in PostgreSQL, we might define as:
CREATE TABLE sales (
id BIGINT PRIMARY KEY,
sale_date DATE NOT NULL,
amount DECIMAL(10, 2)
) PARTITION BY RANGE (sale_date);
CREATE TABLE sales_2024_q1 PARTITION OF sales
FOR VALUES FROM ('2024-01-01') TO ('2024-04-01');
CREATE TABLE sales_2024_q2 PARTITION OF sales
FOR VALUES FROM ('2024-04-01') TO ('2024-07-01');
-- And so on for other partitions
4. Dependencies Required
We’d require spring-boot-starter-web to create our REST endpoints:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
Our primary dependency would be spring-boot-starter-data-jpa for database interactions. It bundles Spring Data JPA and Hibernate, the default JPA provider.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
This is the JDBC (Java Database Connectivity) driver for PostgreSQL. The JDBC driver is a crucial software component that enables our Java application to connect to and interact with a PostgreSQL database:
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
5. Setting Up a Spring Boot Project
Here’s a clear example of how to represent a partition key in a Spring Boot and Hibernate setup.
5.1. Database Entity Setup
First, let’s look at the entity. We’ll create a Sales entity and annotate the saleDate field with @PartitionKey to enable Hibernate’s optimizations:
@Entity
@Table(name = "sales")
public class Sales {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@PartitionKey
private LocalDate saleDate;
private BigDecimal amount;
public Sales(Long id, LocalDate saleDate, BigDecimal amount) {
this.id = id;
this.saleDate = saleDate;
this.amount = amount;
}
public Sales() {
}
}
@PartitionKey is a custom annotation that signals Hibernate that this column will be the basis for table partitioning in the database. This annotation is only present in Hibernate 6.2 and later.
Next, we define our repository, which extends JpaRepository to leverage Spring Data JPA’s power for data access:
@Repository
public interface SalesRepository extends JpaRepository<Sales, Long> {
}
5.2. Design Controller to Test Partition
Now, let’s create a controller to interact with our Sales data. The testPartition() and getAllPartition() methods demonstrate saving a new Sales record. We need to consider that with a partitioned table, the database will automatically place this record into the correct partition based on the saleDate:
@RestController
public class Controller {
@Autowired
SalesRepository salesRepository;
@GetMapping
public ResponseEntity<List<Sales>> getAllPartition() {
return ResponseEntity.ok()
.body(salesRepository.findAll());
}
@GetMapping("add")
public ResponseEntity testPartition() {
return ResponseEntity.ok()
.body(salesRepository.save(new Sales(104L, LocalDate.of(2025, 02, 01),
BigDecimal.valueOf(Double.parseDouble("8476.34d")))));
}
}
Finally, we’ve the application.properties file, where we configure our database connection. We also have to update the username and password as per the DB:
spring.application.name=partitionKeyDemo
# PostgreSQL connection properties
spring.datasource.url=jdbc:postgresql://localhost:5432/salesTest
spring.datasource.username=username
spring.datasource.password=password
5.3. Output
Now, when we run our application and hit http://localhost:8080/add , we can see the row going in the proper partition in PostgreSQL DB:
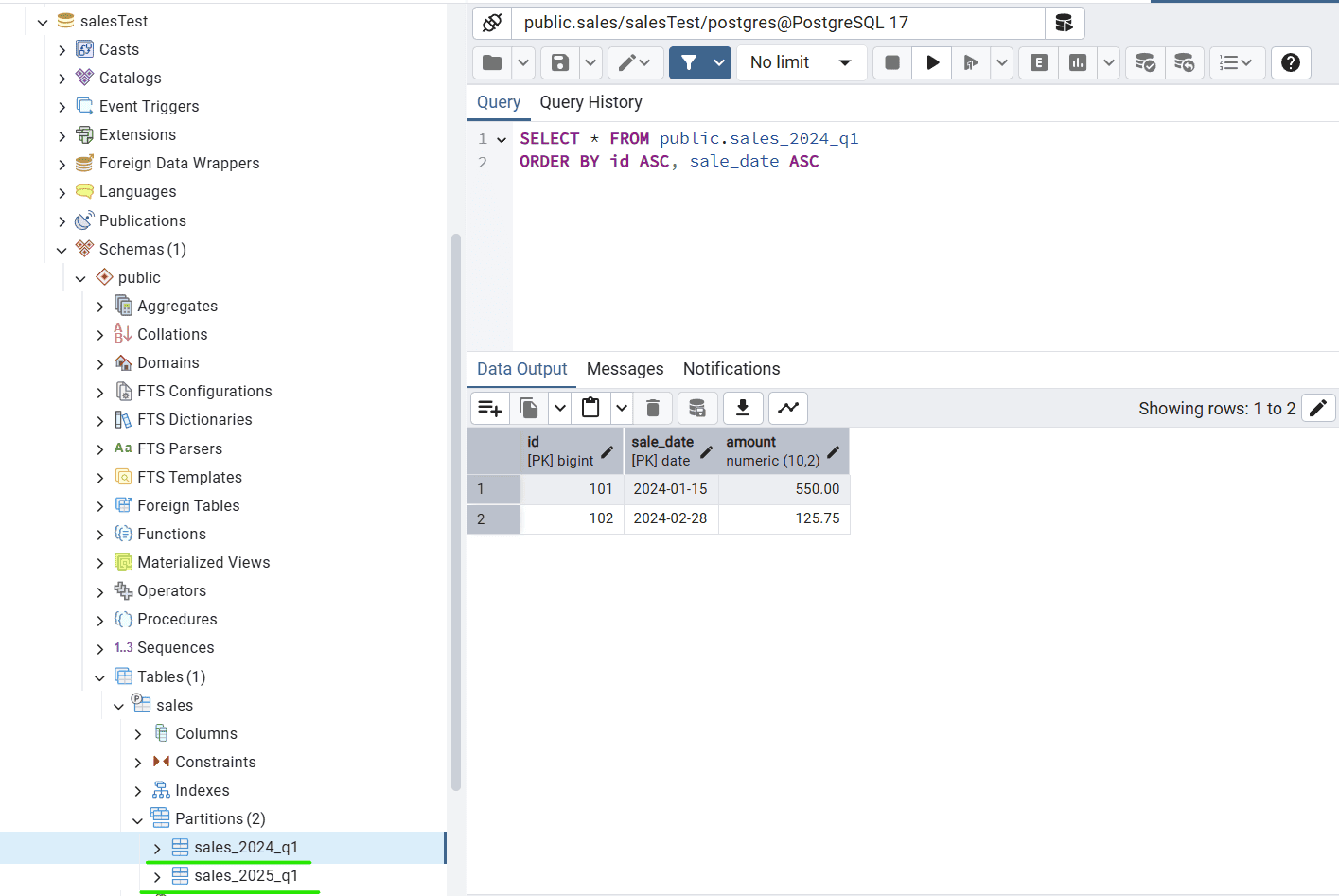
Here we can see two partitions created on the left pane. Then, we can run a query to fetch the row inserted in the correct partition automatically:
SELECT * FROM public.sales_2025_q1;
6. Optimizing Queries With Partitioning
To truly benefit from partitioning, we must design our queries carefully. Let’s consider a scenario where we want to find all sales for a specific date. A well-designed query would look something like this:
SELECT * FROM sales WHERE sale_date = '2025-02-01';
In this case, the database can use the partition key (sale_date) to immediately identify and search only the partition corresponding to ‘2025-02-01’, completely ignoring all other partitions. This is a highly efficient operation.
However, if we run a query that does not include the partition key, such as:
SELECT * FROM sales WHERE amount > 5000;
The database will be forced to scan every single partition to find the matching records. This type of query is known as a global scan, and it’ll likely perform much worse than a query on a non-partitioned, properly indexed table.
7. Conclusion
In this tutorial, we looked at how combining Hibernate’s entity mapping with database-level partitioning we can keep performance consistent as data grows. Partitioning is a powerful technique for scaling our relational databases to handle massive datasets.
While the implementation resides at the database level, Hibernate and Spring Boot provide the necessary tools to interact with these structures seamlessly. At the same time, it is necessary to build queries involving the partition column to use the benefits of the partitioned key.
As always, the code for this article is available over on GitHub. The post PartitionKey in Hibernate: A Practical Guide for Spring Boot first appeared on Baeldung.
Content mobilized by FeedBlitz RSS Services, the premium FeedBurner alternative. | 